
ai 8 min read
Deploying 2:4 Sparsity with FP8 on Hopper: A Production Cookbook
Learn how to implement 2:4 sparsity with FP8 on Hopper for enhanced LLM performance in production environments.
#sparsity
#fp8
#hopper
3 articles
Learn how to implement 2:4 sparsity with FP8 on Hopper for enhanced LLM performance in production environments.

Explore how dynamic sparsity and unstructured kernels drive efficiency in AI with token-aware compute skipping and more.
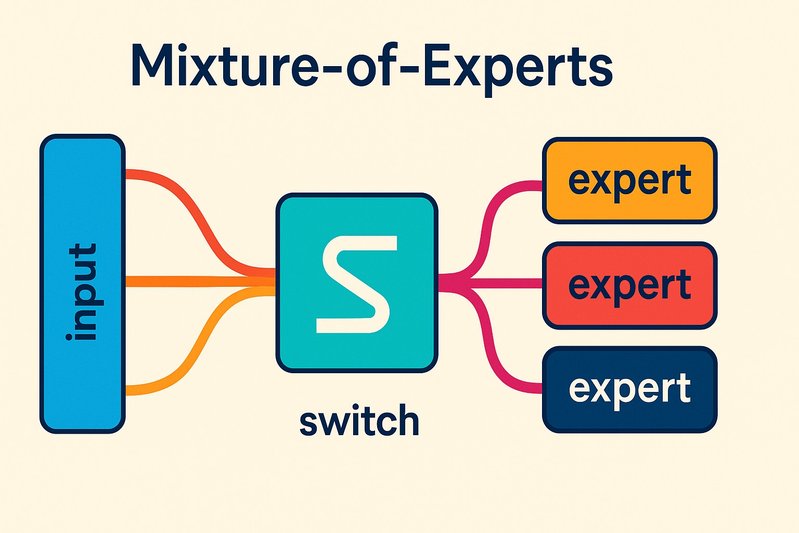
Explore how top-1 routing and expert pruning can drastically enhance MoE performance, reducing compute by 50% with optimal runtimes.
Ad space (disabled)
Vous pouvez choisir quels cookies vous souhaitez autoriser. Certains cookies sont nécessaires au fonctionnement du site.
Ces cookies sont essentiels au fonctionnement du site (navigation, préférences de langue, etc.).
Nous aident à comprendre comment les visiteurs utilisent notre site pour l'améliorer.
Permettent d'afficher des publicités pertinentes. Requis pour afficher Google AdSense.