markdown
Le plan directeur de Home Mixer clarifie l’architecture de flux multi-étapes de X
Une dissection technique des sources de récupération, du classement léger/lourd, des couches de sécurité et du mélange de flux comme documenté dans twitter/the-algorithm
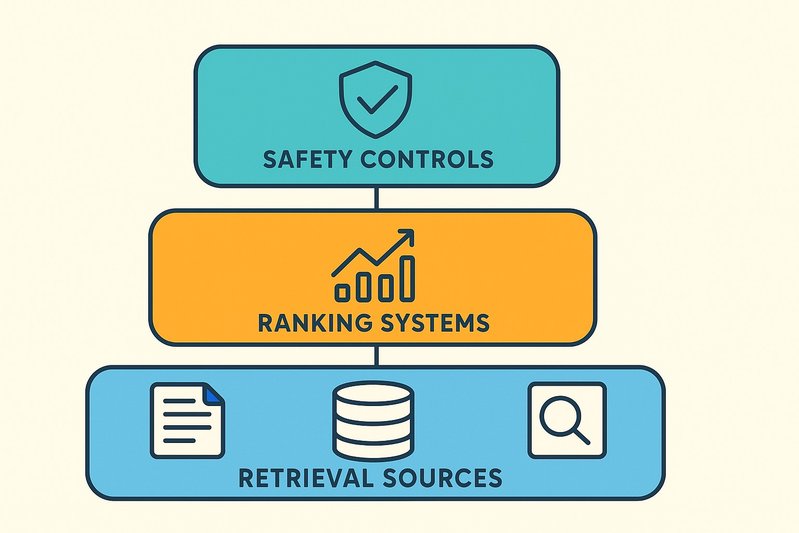
La chronologie Home sur X n’est pas un modèle unique; c’est un pipeline en couches qui fusionne la récupération de graphes, l’inférence communautaire, le classement multi-étapes et les mélangeurs tenant compte des politiques dans un flux en temps réel. Le plan directeur Home Mixer open source expose cette structure clairement: une cascade commence par un large rappel de candidats des sources sociales et communautaires, se rétrécit rapidement avec un classeur léger avec une faible latence, puis améliore la qualité avec un classeur lourd plus riche avant que les contrôles post-classement et les règles de sécurité façonnent le résultat final. Le résultat est un système conçu pour l’étendue, la précision et les garde-fous—sans publier de deltas A/B post-changement ou de métriques d’optimisation du début de 2026.
Cet article cartographie le flux de données de bout en bout et explique où chaque composant se situe, ce qu’il consomme et comment il influence le flux Home. Il décrit également les “zones d’atterrissage” d’optimisation pratique à chaque étape—récupération, classement, re-classement et exécution—et clarifie la gestion des démarrages à froid comme une conséquence directe de l’architecture. Les lecteurs apprendront comment Home Mixer orchestre les sources de candidats, ce que font réellement les classeurs légers et lourds, comment la diversité et l’application de la sécurité gouvernent le dernier kilomètre et où les contraintes d’ingénierie (latence, requêtes d’index, débit) limitent ce qui est possible. Les repères numériques spécifiques restent indisponibles publiquement; l’accent ici est mis sur la structure, les responsabilités et les surfaces d’optimisation.
Détails d’architecture et d’implémentation
Flux de données de bout en bout à travers Home Mixer
Une requête Home entre dans le Home Mixer—un orchestrateur qui coordonne l’assemblage des candidats, le classement multi-étapes et le mélange final dans une chronologie défilable. Le flux de données suit un modèle classique, à grande échelle de recommandation:
- Assemblage des candidats: Récupérer une large gamme de candidats de tweet provenant de multiples sources: expansions sociales-graphiques (abonnements et bords d’engagement), voisins de la structure communautaire et autres mélangeurs qui mettent l’accent sur la fraîcheur et l’ampleur thématique.
- Pré-mélange du classement: Combiner et dédupliquer les candidats de ces sources, en imposant des plafonds précoces par source et des portails de fraîcheur/qualité de base pour limiter la charge en aval.
- Passage du classeur léger: Appliquer un modèle rapide et limité en fonctionnalités pour trier rapidement le pool sous de stricts budgets de latence. Cette étape priorise le rappel des prétendants probables tout en filtrant les éléments de faible pertinence évidente.
- Passage du classeur lourd: Évaluer le sous-ensemble survivant avec des fonctionnalités plus riches et une modélisation plus complexe pour estimer les propensions pour plusieurs actions d’engagement. La calibration et l’alignement des objectifs se font ici.
- Pile de contrôle post-classement: Imposer des contraintes de diversité, des règles de visibilité et l’application de politiques de sécurité/d’entreprise. Cette pile dirige la distribution de l’exposition, minimise les résultats nuisibles et aligne l’ordre final avec les contraintes de produit.
- Mélange et sortie finaux: Le Home Mixer compose la liste classée dans la chronologie, équilibrant abonnements et recommandations et garantissant une expérience utilisateur cohérente.
Le plan directeur met l’accent sur l’orchestration à travers plusieurs sources et couches, non pas un modèle monolithique “un modèle pour les gouverner tous”.
Récupération de candidats à partir de signaux de graphes et communautaires
La récupération est fondée sur deux piliers:
- Bordures sociales: Le graphe de suivi et les bordures d’engagement (par exemple, interactions) produisent des candidats qui reflètent une affinité directe et de voisins proches. Cette voie capitalise sur des liens forts et des interactions récentes pour ancrer le flux dans des sources familières.
- Structures communautaires: Le regroupement semblable à SimClusters regroupe les utilisateurs et le contenu par intérêts partagés. La récupération basée sur la communauté ajoute de l’ampleur thématique, de la découverte à long terme et de la pertinence lorsque les connexions directes sont rares.
Ces sources se connectent à des mélangeurs qui considèrent également:
- Fraîcheur et activité en temps réel: Préférence pour le contenu récent et actif pour maintenir la vitalité du flux.
- Contrôles de déduplication: Suppression précoce des doublons ou quasi-doublons pour économiser sur le budget de classement et réduire les impressions répétitives.
Le plan directeur explique le quoi et le pourquoi de la récupération mais n’énumère pas des métriques de rappel spécifiques ou des augmentations par source; ces détails restent indisponibles publiquement.
Stratégies de mélange des sources avant le classement
Avant que tout modèle ne s’applique, le Home Mixer équilibre abonnements, recommandations et ampleur communautaire pour produire un pool de candidats qui n’est ni trop étroit ni trop dispersé. Les objectifs pratiques à ce stade comprennent:
- Garantir que les abonnements et les liens forts restent bien représentés.
- Introduire des recommandations exploratoires qui élargissent la couverture thématique.
- Éviter la dépendance excessive à toute source unique sans un dispositif explicite de bandit.
Les matériaux publics ne divulguent pas les politiques d’exploration paramétrées, les algorithmes formels de bandit ou leur réglage. Le mélange est présent; les spécificités des politiques d’exploration détaillées ne le sont pas.
Responsabilités du classeur léger
Le classificateur léger est la première porte de modélisation sur un grand ensemble de candidats. Ses traits caractéristiques:
- Sous-ensembles de fonctionnalités: Un inventaire de fonctionnalités plus petit et plus rapide priorise des signaux faciles à calculer et généralement prédictifs.
- Filtrage: Élimination rapide des candidats de faible pertinence ou de faible qualité pour réduire l’ensemble pour une évaluation plus approfondie.
- Contraintes de latence: Les budgets serrés imposent la simplicité du modèle, des caractéristiques approximatives et des stratégies de traitement par lots agressives.
- Filtrage rapide: Les heuristiques pratiques (par ex. seuils de qualité minimale) complètent souvent les scores appris pour maximiser le débit.
Parce que ce passage est freiné par le temps et le coût, son travail est de maintenir un rappel élevé de bons articles, pas de classer parfaitement le flux.
Responsabilités du classeur lourd
Le classeur lourd applique des fonctionnalités plus riches et une modélisation plus complexe à un ensemble réduit:
- Ingestion de fonctionnalités riches: Les caractéristiques de graphique, les interactions historiques et les signaux de contenu sont fusionnés pour affiner la pertinence.
- Estimation de la propension multi-action: Prédire des propensions pour des actions d’engagement telles que les clics, les mentions “j’aime”, les retweets et les réponses; la logique en aval peut agréger ou mélanger ces signaux pour refléter la qualité de la session.
- Alignement de la calibration: Des ajustements garantissent que les scores prédits correspondent aux résultats observés et se combinent de manière cohérente à travers les actions.
Cette étape se concentre sur la précision, la nuance et l’alignement avec les métriques de session à long terme, dans un budget de latence plus souple—mais toujours limité.
Pile de contrôle post-classement: diversité, sécurité et politique
Après le classeur lourd, une pile de contrôle façonne l’exposition:
- Contraintes de diversité: Empêcher les sources ou les sujets répétitifs; promouvoir une exposition variée des créateurs et des contenus.
- Règles de visibilité et logique d’affaires: Imposer des plafonds au niveau des produits, des règles de proéminence et d’autres exigences opérationnelles.
- Application de la sécurité et des politiques: Réduire l’exposition à des contenus nuisibles ou violant les politiques via des pré-filtres et des vérifications post-classement. Les ajustements tenant compte de la sécurité font partie de la conception.
Ces contrôles échangent délibérément une partie de l’engagement brut contre un flux qui répond aux normes de sécurité et de politique.
Infrastructure d’intégration et de fonctionnalités
Les représentations des utilisateurs et des articles fournissent le tissu conjonctif:
- Intégrations dérivées de graphes: Encapsulent la proximité sociale et l’appartenance communautaire.
- Signaux de contenu: Représentent les aspects texte, image ou vidéo d’un tweet—bien que les matériaux publics n’énumèrent pas de précisions trans-modales.
- Interactions historiques: Transforment le comportement passé d’un utilisateur en signaux personnalisés.
Le système dépend de pipelines de fonctionnalités robustes et d’une infrastructure d’intégration; l’empreinte mémoire, la cadence de rafraîchissement et la fraîcheur des données d’entraînement sont mentionnées comme considérations critiques, sans divulguer les budgets numériques.
Limites d’ingénierie d’exécution
À l’échelle de production, la qualité est inséparable de la performance:
- Distributions de latence: Les budgets p50/p95/p99 doivent être respectés de bout en bout; les valeurs exactes ne sont pas publiquement publiées.
- Chemins de requête ANN: Les indices des plus proches voisins approchés et les traversées de graphes soutiennent la récupération sous des SLA serrés; les ajustements de paramètres affectent le rappel, la précision et le coût.
- Matériel/débit: Le traitement par lots, la mise en cache et l’inférence quantifiée aident à presser la performance dans des enveloppes de calcul; encore une fois, les chiffres spécifiques ne sont pas publics.
- Respect des SLA et coût: Le système est décrit en termes d’équilibre entre vitesse, qualité et coût; les compromis quantitatifs ne sont pas divulgués.
L’architecture souligne ces contraintes sans donner les chiffres de performance sous-jacents.
Tableaux de comparaison
Responsabilités du classeur léger vs du classeur lourd
| Dimension | Classeur léger | Classeur lourd |
|---|---|---|
| Objectif principal | Filtrage rapide avec un rappel élevé | Classement et ordonnancement haute précision |
| Portée des fonctionnalités | Sous-ensemble; facile à calculer | Riches, fonctionnalités diversifiées |
| Complexité de modélisation | Plus simple, priorité à la latence | Plus complexe, priorité à la précision |
| Budget de latence | Serré | Plus souple (toujours limité) |
| Sorties | Liste restreinte de candidats viables | Propensions multi-actions et scores calibrés |
| Mode d’échec à éviter | Sur-élimination des bons éléments | Mauvaise calibration ou sur-ajustement sous des limites de latence |
Sources de récupération et mélangeurs (pré-classement)
| Source | Points forts | Risques/Coûts | Contrôles précoces |
|---|---|---|---|
| Bordures sociales (abonnements, engagements) | Forte affinité, haute précision | Risque de chambre d’écho | Plafonds par source; portails de fraîcheur |
| Structures communautaires (clusters) | Ampleur thématique, découverte à long terme | Précision plus faible si mal alignée | Déduplication; contrôles de qualité de base |
| Mélangeurs axés sur la fraîcheur | Pertinence en temps réel | Volatilité potentielle | Fenêtres temporelles; équilibre des sources |
Pré-mélange du classement vs contrôle post-classement
| Couche | Objectif | Mécanismes | Remarques |
|---|---|---|---|
| Pré-mélange du classement | Assembler un pool de candidats large et dé-dupliqué | Plafonds de source, fraîcheur, filtres légers | Évite la surcharge des classificateurs; établit une base de diversité |
| Contrôle post-classement | Façonner l’exposition après le classement | Contraintes de diversité, règles d’affichage, sécurité/politique | Aligne les résultats avec les objectifs de produit et de sécurité |
Bonnes pratiques
Zones d’atterrissage d’optimisation par étape
Le plan directeur montre clairement où les améliorations s’attachent généralement:
-
Augmentations de récupération:
-
Ajouter ou affiner les sources de graphes/communautés pour augmenter le rappel des candidats pertinents.
-
Ajuster les paramètres ANN et de traversée pour améliorer le rappel@K sous les limites de latence et de mémoire.
-
Renforcer les signaux de fraîcheur et les pré-filtres pour réduire le gaspillage en aval.
-
Familles de modèles de classeurs:
-
Évoluer les architectures du classeur léger pour un meilleur rappel à latence fixe; distiller les modèles plus lourds uniquement si le budget le permet.
-
Élargir les objectifs du classeur lourd à des configurations multitâches qui capturent des actions d’engagement variées, avec une calibration soignée.
-
Politiques de re-classement:
-
Ajuster les règles de diversité et de nouveauté pour améliorer la qualité des sessions sans sacrifier la sécurité.
-
Auditer l’interaction entre la logique d’affaires et les filtres de sécurité pour minimiser la suppression involontaire de contenu précieux.
-
Améliorations des fonctionnalités et des intégrations:
-
Enrichir les intégrations de graphes et communautaires; les calendriers de rafraîchissement et les remplacements sont importants pour la stabilité.
-
Intégrer des signaux de contenu lorsque possible; évaluer les contributions trans-modales via des ablations.
Des hausses spécifiques ou des résultats A/B ne sont pas disponibles publiquement; les conseils ci-dessus découlent des rôles architecturaux plutôt que des deltas rapportés.
Mesure et attribution efficaces
Pour distinguer les gains réels du bruit et éviter le chevauchement des étapes:
-
Mesures de récupération hors ligne:
-
Suivre le rappel@K, le taux de succès et l’NDCG@K tronqué par oracle après avoir ajouté ou ajusté des sources.
-
Mesurer les changements de couverture/diversité et les interactions avec les pré-filtres de sécurité.
-
Mesures de classement hors ligne:
-
Rapporter l’AUC, l’NDCG@K, le MAP et le MRR par type d’action, plus l’erreur de calibration.
-
Résultats en ligne:
-
Surveiller le CTR, la rétention, la profondeur/longueur de session et les taux de rétroaction négative ou de toxicité avec une confiance statistique.
-
Utiliser les intervalles de confiance au niveau des expériences et corriger les tests multiples entre variantes.
-
Décompositions par cohorte et localité:
-
Évaluer les nouveaux utilisateurs vs les utilisateurs réguliers, les créateurs vs les consommateurs, et les segments localité/langue pour l’hétérogénéité.
-
Traitement explicite des différences de modalité (texte/image/vidéo) là où applicable.
-
Comptabilité des compromis:
-
Consigner la latence p50/p95/p99 de bout en bout; suivre le temps d’inférence, les coûts de requête ANN et le coût par 1 000 requêtes.
-
Documenter les taux d’événements de sécurité et les effets de distribution (par exemple, exposition des créateurs) lorsque les règles de re-classement changent.
Où les chiffres ne sont pas publics, les équipes doivent tout de même les collecter et les rapporter en interne pour appuyer les décisions.
Gestion du démarrage à froid en tant que conséquence architecturale
Les cohortes de démarrage à froid et d’historique rare s’appuient sur les éléments déjà en place:
- Priors des communautés et du graphe: La récupération communautaire et les intégrations de graphe fournissent des proxys d’intérêt immédiats lorsque l’historique personnel est mince.
- Signaux basés sur le contenu: Les fonctionnalités de texte et de médias aident à identifier les intérêts probables même avant l’existence d’arêtes de suivi.
- Budgets d’exploration via le mélange: L’exposition précoce à des sujets diversifiés lance une rétroaction utile sans détails de bandit explicites publiés.
Pour vérifier les progrès, suivre:
- NDCG@K hors ligne et MAP dans les cohortes à zéro et quelques interactions.
- Temps en ligne avant le premier engagement, profondeur de la première session et courbes de rétention précoce.
- Tout changement dans l’exposition à l’exploration, les écrans de sécurité ou la latence pour ces cohortes.
Les améliorations de démarrage à froid sont les plus crédibles lorsqu’elles ne dégradent pas la performance des utilisateurs fréquents ou les résultats de sécurité.
Garde-fous opérationnels pour maintenir la qualité intacte
Les contraintes d’ingénierie déterminent ce qui est déployable:
- Respecter les distributions de SLA: Concevoir des divisions léger/lourd et des paramètres ANN pour atteindre les cibles p50/p95/p99; les spécificités ne sont pas publiquement divulguées, mais l’application est non négociable.
- Utiliser les approximations judicieusement: La quantification, la mise en cache et le traitement par lots devraient inclure des contrôles de qualité (deltas AUC/NDCG) pour s’assurer que les gains de vitesse ne grignotent pas silencieusement le classement.
- Surveiller le coût et la disponibilité: Le débit et le coût par demande déterminent l’échelle pratique; publier des tableaux de bord internes pour maintenir l’optimisation honnête.
- La sécurité reste en boucle: Tout changement de récupération ou de classement doit être évalué avec les filtres de sécurité/politique pour éviter une exposition nuisible non intentionnelle. 🛡️
Conclusion
Le plan directeur de Home Mixer rend un point indubitable: la chronologie Home de X est un système à plusieurs étapes conçu pour équilibrer l’échelle, la personnalisation et la sécurité à travers des limites architecturales explicites. La récupération s’appuie sur les signaux sociaux et communautaires pour l’étendue; un classeur léger filtre rapidement sous une faible latence; un classeur lourd ajoute de la profondeur avec une modélisation multi-actions et de la calibration; et les couches post-classement appliquent la diversité, la visibilité et la sécurité. Les intégrations et les pipelines de fonctionnalités relient l’ensemble, tandis que les contraintes d’exécution et les SLA tracent des lignes dures autour de ce qui est faisable en production.
Principaux enseignements:
- Le flux Home est un pipeline orchestré, pas un modèle unique; les mélangeurs et les règles de re-classement sont des citoyens de première classe.
- L’étendue de récupération plus la profondeur de classement léger/lourd est l’épine dorsale; les règles de diversité et de sécurité dirigent la sortie finale.
- Les “zones d’atterrissage” d’optimisation existent à chaque étape—récupération, classeurs, re-classement et exécution—mais des métriques publiques spécifiques sont indisponibles.
- La gestion des démarrages à froid découle de l’architecture: les priors communautaires/de graphe, les signaux de contenu et l’exploration précoce.
- La performance, le coût et la sécurité doivent être mesurés ensemble; la latence p50/p95/p99 et la calibration devraient figurer dans chaque liste de vérification de version.
Prochaines étapes pour les praticiens:
- Cartographier votre propre pipeline à ces étapes et identifier les goulots d’étranglement par étape.
- Instrumenter à la fois les métriques hors ligne (AUC, NDCG@K, MAP, MRR) et en ligne (CTR, rétention, session, sécurité) avec des découpages par cohorte.
- Prioriser le rappel de récupération et le rappel du classeur léger à latence fixe avant d’accroître la complexité du classeur lourd.
- Renforcer les politiques de sécurité et de diversité de concert avec les changements de rappel et de classement.
L’architecture offre un plan directeur durable pour des flux à grande échelle: élargir intelligemment, classer en étapes et appliquer des garde-fous qui maintiennent l’expérience saine et cohérente—même lorsque les métriques d’optimisation spécifiques restent derrière le rideau.