El Prototipo de Home Mixer Aclara la Arquitectura de Alimentación de Múltiples Etapas de X
Una disección técnica de las fuentes de recuperación, evaluación ligera/pesada, capas de seguridad y mezcla de fuentes según se documenta en twitter/the-algorithm
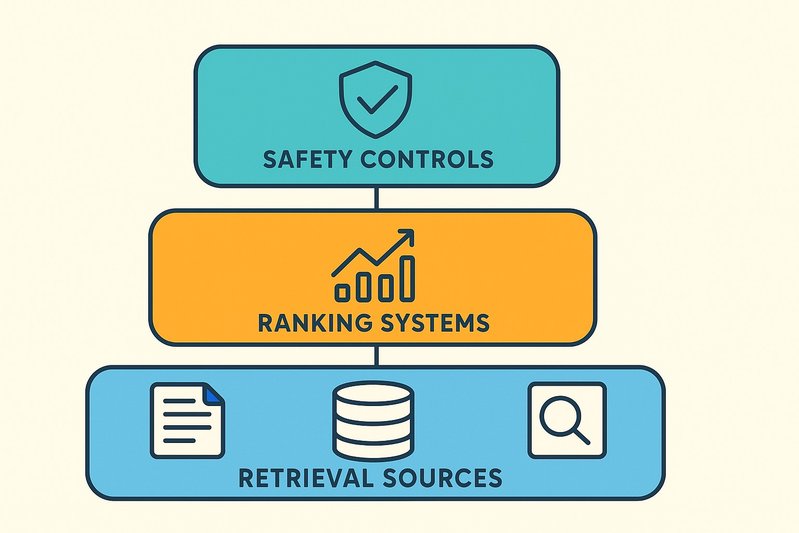
La línea de tiempo de Inicio en X no es un modelo único; es una canalización en capas que fusiona la recuperación de gráficos, la inferencia comunitaria, la clasificación en múltiples etapas y mezcladores conscientes de políticas en un feed en tiempo real. El prototipo de Home Mixer de código abierto expone esta estructura de manera clara: una cascada que empieza con un amplio recuerdo de candidatos de fuentes sociales y comunitarias, se estrecha rápidamente con un Light Ranker ajustado a bajas latencias, y luego mejora la calidad con un Heavy Ranker más rico antes de que los controles post-clasificación y las reglas de seguridad moldeen el resultado final. El resultado es un sistema diseñado para amplitud, precisión y medidas de seguridad, sin publicar deltas de A/B por cambio o métricas de optimización a principios de 2026.
Este artículo traza el flujo de datos de extremo a extremo y explica dónde se ubica cada componente, qué consume y cómo influye en el feed de Inicio. También describe “zonas de aterrizaje” de optimización prácticas en cada etapa—recuperación, clasificación, re-clasificación y tiempo de ejecución—y aclara el manejo de inicio en frío como una consecuencia directa de la arquitectura. Los lectores aprenderán cómo el Home Mixer orquesta las fuentes de candidatos, qué hacen realmente los rankers Light y Heavy, cómo la diversidad y la seguridad gobiernan la última milla, y dónde las limitaciones de ingeniería (latencia, consultas de índice, rendimiento) limitan lo que es posible. Las métricas numéricas específicas siguen siendo no disponibles públicamente; el énfasis aquí está en la estructura, responsabilidades y superficies de optimización.
Detalles de Arquitectura/Implementación
Flujo de datos de extremo a extremo a través del Home Mixer
Una solicitud de Inicio entra al Home Mixer—un orquestador que coordina el ensamblaje de candidatos, clasificación en múltiples etapas y mezcla final en una línea de tiempo desplazable. El flujo de datos sigue un patrón de recomendación estándar de gran escala:
- Ensamblaje de candidatos: Recuperar una amplia variedad de candidatos de tweet de múltiples fuentes: expansiones del grafo social (seguimientos y bordes de interacción), vecinos de la estructura comunitaria y otros mixers que enfatizan la frescura y amplitud temática.
- Mezcla previo a la clasificación: Combinar y desduplicar candidatos de estas fuentes, imponiendo límites iniciales por fuente y puertas de frescura/calidad básica para limitar la carga posterior.
- Paso del Light Ranker: Aplicar un modelo rápido y con características limitadas para eliminar rápidamente elementos bajo presupuestos de latencia ajustados. Esta etapa prioriza el recuerdo de contendientes probables mientras filtra elementos obviamente irrelevantes.
- Paso del Heavy Ranker: Puntuación del subconjunto sobreviviente con características más ricas y un modelado más complejo para estimar propensiones para múltiples acciones de interacción. La calibración y alineación de objetivos ocurren aquí.
- Pila de control post-clasificación: Imponer restricciones de diversidad, reglas de visibilidad y aplicación de políticas de seguridad/negocio. Esta pila dirige la distribución de exposición, minimiza resultados perjudiciales y alinea el orden final con las restricciones del producto.
- Mezcla final y salida: El Home Mixer compone la lista clasificada en la línea de tiempo, equilibrando seguimientos y recomendaciones y asegurando una experiencia de usuario coherente.
El prototipo enfatiza la orquestación a través de múltiples fuentes y capas, no un “modelo único para gobernarlos a todos”.
Recuperación de candidatos a partir de señales de grafo y comunidad
La recuperación se basa en dos pilares:
- Bordes sociales: El grafo de seguimiento y los bordes de interacción (por ejemplo, interacciones) producen candidatos que reflejan afinidad directa y de vecinos cercanos. Esta vía capitaliza los lazos fuertes y las interacciones recientes para anclar el feed en fuentes familiares.
- Estructuras comunitarias: La agrupación similar a SimClusters agrupa a los usuarios y contenido por intereses compartidos. La recuperación basada en comunidades añade amplitud temática, descubrimiento de larga cola y relevancia cuando las conexiones directas son escasas.
Estas fuentes se conectan a mezcladores que también consideran:
- Frescura y actividad en tiempo real: Preferencia por contenido reciente y activo para mantener la vitalidad del feed.
- Controles de desduplicación: Eliminación temprana de duplicados o casi duplicados para ahorrar presupuesto de clasificación y reducir impresiones repetitivas.
El prototipo explica el qué y por qué de la recuperación, pero no enumera métricas específicas de recuerdo o aumentos por fuente; esos detalles siguen no disponibles públicamente.
Estrategias de mezcla de fuentes antes de la clasificación
Antes de que cualquier modelo se dispare, el Home Mixer equilibra los seguimientos, recomendaciones y amplitud comunitaria para producir un conjunto de candidatos que no sea ni demasiado estrecho ni demasiado desenfocado. Los objetivos prácticos en esta etapa incluyen:
- Asegurarse de que los seguimientos y los lazos fuertes estén bien representados.
- Introducir recomendaciones exploratorias que amplíen la cobertura temática.
- Evitar la sobre-dependencia en cualquier fuente única sin maquinaria explícita de bandido.
Los materiales públicos no revelan políticas de exploración parametrizadas, algoritmos formales de bandido, ni su ajuste. La mezcla está presente; los detalles específicos de las políticas de exploración no lo están.
Responsabilidades del Light Ranker
El Light Ranker es la primera puerta de modelado a través de un gran conjunto de candidatos. Sus rasgos definitorios:
- Subconjuntos de características: Un inventario más pequeño y rápido de características que prioriza señales que son baratas de calcular y generalmente predictivas.
- Puerta: Eliminación rápida de candidatos de baja relevancia o baja calidad para reducir el conjunto para puntuación más profunda.
- Restricciones de latencia: Presupuestos ajustados fuerzan la simplicidad del modelo, características aproximadas y estrategias agresivas de agrupamiento.
- Filtrado rápido: Heurísticas prácticas (por ejemplo, umbrales mínimos de calidad) a menudo complementan las puntuaciones aprendidas para maximizar el rendimiento.
Debido a que este paso está limitado por el tiempo y el costo, su trabajo es mantener un alto recuerdo de buenos elementos, no clasificar perfectamente el feed.
Responsabilidades del Heavy Ranker
El Heavy Ranker aplica características más ricas y un modelado más complejo a un conjunto más reducido:
- Ingesta de características ricas: Las características del gráfico, interacciones históricas y señales de contenido se fusionan para refinar la relevancia.
- Estimación de propensidades multi-acción: Predecir propensiones para acciones de interacción como clics, me gusta, retweets y respuestas; la lógica posterior puede agregar o mezclar estas señales para reflejar la calidad de la sesión.
- Alineación de calibración: Los ajustes aseguran que las puntuaciones predichas coincidan con los resultados observados y se combinen de manera coherente a través de acciones.
Esta etapa se centra en la precisión, el matiz y la alineación con métricas de sesión a más largo plazo, dentro de un presupuesto de latencia más flexible, pero aún limitado.
Pila de control post-clasificación: diversidad, seguridad y política
Después del Heavy Ranker, una pila de control da forma a la exposición:
- Restricciones de diversidad: Proteger contra fuentes o temas repetitivos; promover la exposición variada de creadores y contenido.
- Reglas de visibilidad y lógica de negocio: Impone límites a nivel de producto, reglas de prominencia y otros requisitos operativos.
- Aplicación de seguridad y políticas: Reducir la exposición a contenido dañino o violatorio de políticas mediante pre-filtros y revisiones post-clasificación. Los ajustes conscientes de la seguridad son parte del diseño.
Estos controles deliberadamente intercambian cierta interacción cruda por un feed que cumpla con los estándares de seguridad y política.
Infraestructura de embeddings y características
Las representaciones de usuarios e ítems proporcionan el tejido conectivo:
- Embeddings derivados de gráfico: Encapsulan la proximidad social y la pertenencia comunitaria.
- Señales de contenido: Representan aspectos de texto, imagen o video de un tweet, aunque los materiales públicos no enumeran especificaciones cruzadas de modalidad.
- Interacciones históricas: Traducen el comportamiento pasado de un usuario en señales personalizadas.
El sistema depende de robustas tuberías de características e infraestructura de embeddings; la huella de memoria, la cadencia de actualización y la frescura de los datos de entrenamiento se mencionan como consideraciones operativas clave, sin divulgar presupuestos numéricos.
Límites de ingeniería en tiempo de ejecución
A escala de producción, la calidad es inseparable del rendimiento:
- Distribuciones de latencia: Se deben respetar los presupuestos p50/p95/p99 de extremo a extremo; los valores exactos no se publican públicamente.
- Rutas de consultas/ANN: Los índices de vecinos más cercanos aproximados y los recorridos de gráficos respaldan la recuperación bajo SLA estrictos; el ajuste de parámetros afecta el recuerdo, la precisión y el costo.
- Hardware/rendimiento: El agrupamiento, almacenamiento en caché y la inferencia cuantizada ayudan a exprimir el rendimiento dentro de los límites informáticos; nuevamente, las cifras específicas no se publican.
- Adhesión a SLA y costos: El sistema se describe en términos de equilibrar velocidad, calidad y costo; no se revelan los compromisos cuantitativos.
La arquitectura resalta estas restricciones sin proporcionar los números de rendimiento subyacentes.
Tablas Comparativas
Responsabilidades de Light vs Heavy Ranker
| Dimensión | Light Ranker | Heavy Ranker |
|---|---|---|
| Objetivo principal | Filtrado rápido con alto recuerdo | Puntuación y ordenamiento de alta precisión |
| Alcance de características | Subconjunto; barato de calcular | Características ricas y diversas |
| Complejidad del modelado | Más simple, primero latencia | Más complejo, primero precisión |
| Presupuesto de latencia | Ajustado | Más flexible (aún limitado) |
| Resultados | Lista corta de candidatos viables | Propensiones multi-acción y puntuaciones calibradas |
| Modo de fallo a evitar | Sobre-eliminación de buenos ítems | Desajuste o sobreajuste bajo límites de latencia |
Fuentes de recuperación y mezcladores (pre-clasificación)
| Fuente | Fortalezas | Riesgos/Costos | Controles tempranos |
|---|---|---|---|
| Bordes sociales (seguimientos, interacciones) | Alta afinidad, alta precisión | Riesgo de cámara de eco | Límites por fuente; control de frescura |
| Estructuras comunitarias (clústeres) | Amplitud temática, descubrimiento de larga cola | Menor precisión si está mal alineado | Desduplicación; pantallas de calidad básica |
| Mezcladores enfocados en frescura | Relevancia en tiempo real | Potencial de volatilidad | Ventanas basadas en tiempo; equilibrio de fuentes |
Mezcla pre-clasificación vs control post-clasificación
| Capa | Propósito | Mecanismos | Notas |
|---|---|---|---|
| Mezcla pre-clasificación | Ensamblar un amplio conjunto de candidatos desduplicados | Límites por fuente, frescura, filtros ligeros | Evita sobrecarga de los rankers; establece línea base de diversidad |
| Control post-clasificación | Dar forma a la exposición tras la puntuación | Restricciones de diversidad, reglas de visibilidad, seguridad/política | Alinea resultados con objetivos de producto y seguridad |
Mejores Prácticas
Zonas de aterrizaje de optimización por etapa
El prototipo deja claro dónde suelen estar los puntos de mejora:
-
Aumentaciones de recuperación:
-
Agregar o refinar fuentes de grafo/comunidad para aumentar el recuerdo de candidatos relevantes.
-
Ajustar parámetros de ANN y recorridos para mejorar el recall@K bajo límites de latencia y memoria.
-
Fortalecer señales de frescura y filtros previos para reducir el desperdicio posterior.
-
Familias de modelos de Ranker:
-
Evolucionar arquitecturas de Light Ranker para mejor recuerdo a latencia fija; destilar modelos más pesados solo si los presupuestos lo permiten.
-
Ampliar objetivos de Heavy Ranker a configuraciones multi-tarea que capturen diversas acciones de interacción, con calibración cuidadosa.
-
Políticas de re-clasificación:
-
Ajustar reglas de diversidad y novedad para mejorar la calidad de la sesión sin sacrificar la seguridad.
-
Auditar la interacción entre la lógica de negocio y los filtros de seguridad para minimizar la supresión no intencionada de contenido valioso.
-
Mejoras de características y embeddings:
-
Enriquecer embeddings de grafo y comunidad; los calendarios de actualización y rellenos son importantes para la estabilidad.
-
Integrar señales de contenido donde sea posible; evaluar contribuciones cruzadas de modalidad con ablaciones.
No se encuentran específicos levantamientos o resultados A/B disponibles públicamente; el consejo anterior sigue roles arquitectónicos más que deltas reportados.
Medición y atribución que realmente funciona
Para distinguir mejoras reales del ruido y evitar solapamiento de etapas:
-
Métricas de recuperación offline:
-
Rastrear recall@K, tasa de aciertos y NDCG@K truncado por oráculo después de agregar o ajustar fuentes.
-
Medir cambios en cobertura/diversidad e interacciones con pre-filtros de seguridad.
-
Métricas de clasificación offline:
-
Informar AUC, NDCG@K, MAP y MRR por tipo de acción, además del error de calibración.
-
Resultados online:
-
Monitorear CTR, permanencia, profundidad/longitud de sesión y tasas de retroalimentación negativa o toxicidad con confianza estadística.
-
Usar intervalos de confianza a nivel de experimento y corrección de pruebas múltiples a través de variantes.
-
Desgloses por cohorte y localidad:
-
Evaluar nuevos usuarios vs usuarios intensivos, creadores vs consumidores, y segmentos por localidad/idioma para heterogeneidad.
-
Tratar diferencias de modalidad (texto/imagen/video) explícitamente donde sea aplicable.
-
Contabilidad de compromisos:
-
Registrar latencias p50/p95/p99 de extremo a extremo; rastrear tiempos de inferencia, costos de consultas ANN y costo por 1,000 solicitudes.
-
Documentar tasas de eventos de seguridad y efectos distribucionales (por ejemplo, exposición de creadores) cuando cambian las reglas de re-clasificación.
Donde los números no son públicos, los equipos aún deben recopilarlos e informarlos internamente para respaldar decisiones.
Manejo de inicio en frío como una consecuencia arquitectónica
Las cohortes de inicio en frío y de historia escasa se apoyan en las piezas ya situadas:
- Prioridades de comunidades y grafo: La recuperación basada en comunidades y los embeddings de grafo proporcionan proxies de interés inmediatos cuando la historia personal es escasa.
- Señales basadas en contenido: Las características de texto y medios ayudan a identificar intereses probables incluso antes de que existan bordes de seguimiento.
- Presupuestos de exploración a través de la mezcla: La exposición temprana a temas diversos siembra retroalimentación útil sin publicar detalles explícitos de bandido.
Para verificar el progreso, rastrear:
- NDCG@K y MAP offline en cohortes de cero y pocas interacciones.
- Tiempo online al primer compromiso, profundidad de primera sesión y curvas de retención temprana.
- Cualquier cambio en la exposición de exploración, filtros de seguridad o latencia para estas cohortes.
Las mejoras en inicio en frío son más creíbles cuando no degradan el rendimiento de usuarios intensivos o los resultados de seguridad.
Barandillas operacionales para mantener la calidad intacta
Las restricciones de ingeniería moldean lo que es desplegable:
- Respetar las distribuciones SLA: Diseñar divisiones Light/Heavy y parámetros ANN para cumplir con objetivos p50/p95/p99; los específicos no se divulgan públicamente, pero la aplicación es no negociable.
- Usar aproximaciones con prudencia: La cuantización, almacenamiento en caché y agrupamiento deben incluir verificaciones de calidad (deltas AUC/NDCG) para asegurar que las ganancias en velocidad no erosionen silenciosamente la clasificación.
- Monitorear costos y disponibilidad: El rendimiento y costo por solicitud determinan la escala práctica; publicar tableros internos para mantener la optimización honesta.
- La seguridad se mantiene en el ciclo: Cualquier cambio de recuperación o clasificación debe evaluarse junto con los filtros de seguridad/política para evitar exposiciones dañinas no intencionadas. 🛡️
Conclusión
El prototipo de Home Mixer deja un punto claro: la línea de tiempo de Inicio de X es un sistema de múltiples etapas diseñado para equilibrar escala, personalización y seguridad a través de límites arquitectónicos explícitos. La recuperación aprovecha señales sociales y comunitarias para la amplitud; un Light Ranker filtra rápidamente bajo latencias ajustadas; un Heavy Ranker añade profundidad con modelado multi-acción y calibración; y las capas post-clasificación imponen diversidad, visibilidad y seguridad. Embeddings y tuberías de características tejen todo junto, mientras que las restricciones de tiempo de ejecución y los SLA trazan líneas duras sobre lo que es posible en producción.
Puntos clave:
- El feed de Inicio es una canalización orquestada, no un modelo único; los mezcladores y las reglas de re-clasificación son ciudadanos de primera clase.
- La amplitud de recuperación más la profundidad de clasificación Light/Heavy es la columna vertebral; las reglas de diversidad y seguridad dirigen el resultado final.
- “Zonas de aterrizaje” de optimización existen en cada etapa—recuperación, rankers, re-clasificación y runtime—pero métricas públicas específicas no están disponibles.
- El manejo de inicio en frío surge de la arquitectura: prioridades de comunidad/grafo, señales de contenido y exploración temprana.
- El rendimiento, costo y seguridad deben medirse juntos; latencias p50/p95/p99 y calibración pertenecen a cada lista de verificación de versión.
Próximos pasos para practicantes:
- Mapea tu propia canalización a estas etapas e identifica cuellos de botella por etapa.
- Instrumentar métricas tanto offline (AUC, NDCG@K, MAP, MRR) como online (CTR, permanencia, sesión, seguridad) con desgloses por cohortes.
- Prioriza el recuerdo de recuperación y el recuerdo del Light Ranker a latencia fija antes de expandir la complejidad del Heavy Ranker.
- Fortalece políticas de seguridad y diversidad en sincronía con cambios de recuerdo y clasificación.
La arquitectura ofrece un prototipo duradero para feeds de alta escala: ampliar inteligentemente, clasificar en etapas y hacer cumplir medidas de seguridad que mantengan la experiencia saludable y coherente—aunque las métricas específicas de optimización sigan tras la cortina.