
markdown
FP8 y FP4 Transforman la Economía del Entrenamiento a medida que Blackwell’s Transformer Engine Matures
Precisiones emergentes, hojas de ruta de kernels y patrones de diseño de modelos que remodelarán el entrenamiento de contextos largos
La llegada de Blackwell lleva las GPUs corrientes al territorio de ancho de banda anteriormente reservado para partes del centro de datos. Una sola tarjeta de estación de trabajo ahora puede ofrecer hasta 1.792 TB/s de ancho de banda GDDR7 junto con un Transformer Engine de segunda generación, mientras que la variante profesional amplía la memoria a 48-72 GB y añade MIG para cargas de trabajo particionadas. En ese contexto, la precisión del entrenamiento está cambiando de un estándar BF16 hacia programaciones que explotan FP8 donde los marcos lo permiten, y, con el tiempo, FP4/FP6 en roles más limitados. El premio es sencillo: más tokens por segundo, lotes globales más grandes por GPU y menores huellas de memoria en contextos de secuencia más largos, sin sacrificar la convergencia.
Este artículo muestra cómo cambian las economías del entrenamiento a medida que FP8 y FP4 pasan de ser capacidades de hardware a una realidad de software. Traza el camino desde el entrenamiento BF16 primero a las programaciones conscientes de FP8, explica lo que FP4/FP6 desbloquea primero y cómo adoptarlos de manera segura, mapea la evolución de los kernels de atención para longitudes de secuencias de 2k–8k, detalla la partición de recursos en estaciones de trabajo con MIG, y describe las piezas del compilador y el autotuning que decidirán dónde aterrizan las ganancias. Finalmente, enumera hitos prácticos y pruebas de validación para separar el habilitamiento creíble de las diapositivas de marketing.
De un estándar BF16 a programaciones FP8 impulsadas por un Transformer Engine de segunda generación
Durante los últimos dos años, la precisión mixta BF16 ha sido la base confiable en GPUs de consumo y estaciones de trabajo. Eso sigue siendo cierto hoy para un entrenamiento robusto entre Ada, Hopper, y Blackwell. El cambio estratégico es que las cargas de trabajo de clase transformer se benefician cada vez más cuando los kernels pueden mover partes del cálculo a FP8 mediante recasting asistido por hardware.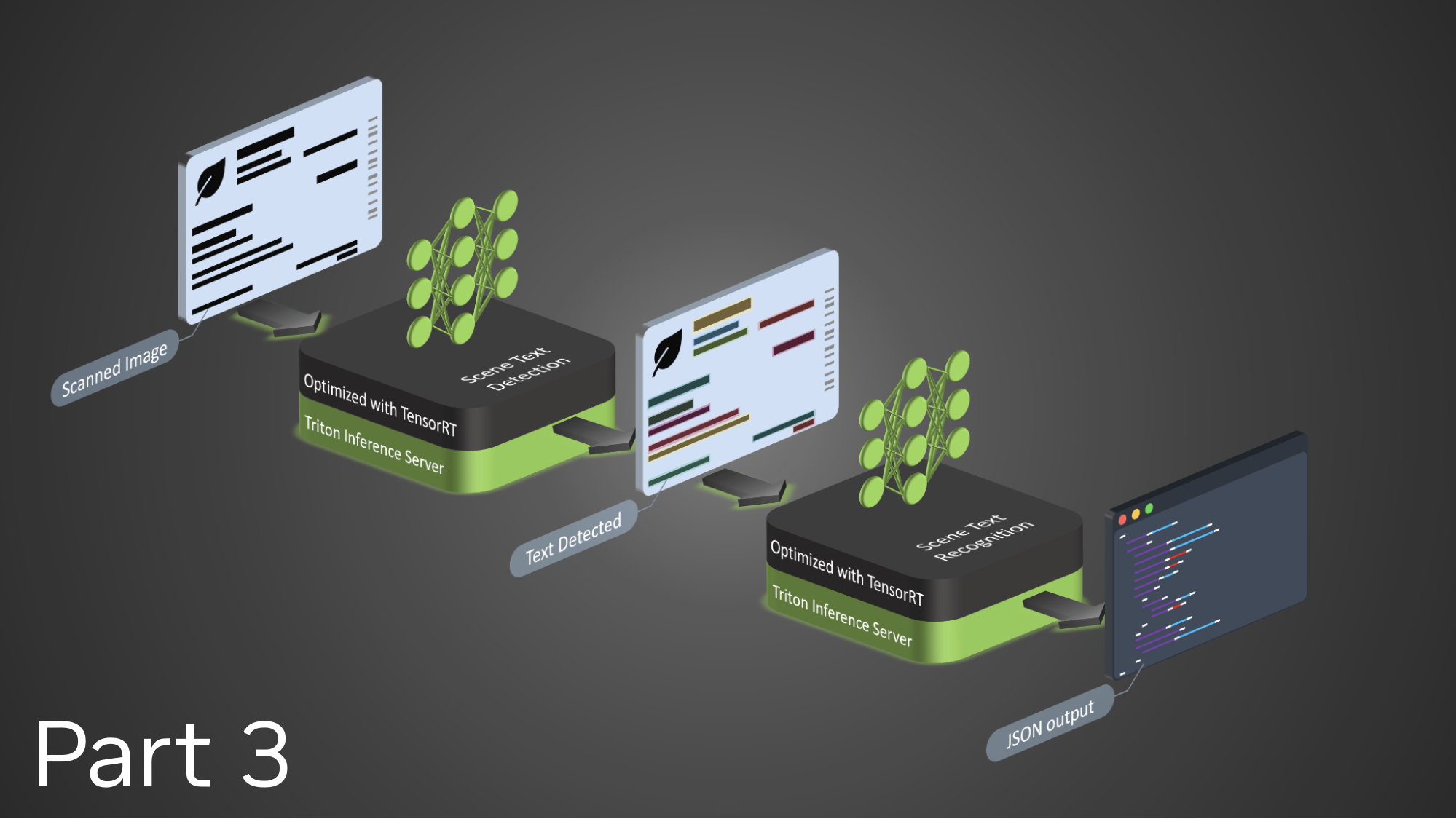
La imagen ilustra la tubería de procesamiento de las GPUs NVIDIA Hopper, presentando una secuencia de componentes que incluyen servidores de inferencia optimizados por TensorRT, módulos de detección y reconocimiento de texto en escenas, y la generación de salida en JSON.
Hopper hizo que el Transformer Engine FP8 se volviera común para el entrenamiento en nodos SXM y lo escaló a través de NVLink/NVSwitch. La posición de NVIDIA en data center Ada también enfatiza las rutas FP8 para transformers. Blackwell extiende esa capacidad a los Tensor Cores de quinta generación y añade un Transformer Engine de segunda generación tanto en tarjetas de consumo como en estaciones de trabajo. El hardware soporta BF16/FP16/TF32/FP8 de manera nativa, con FP4/FP6 introducidos en Blackwell para una reducción de memoria incluso más agresiva.
¿Qué cambia en la práctica cuando las programaciones FP8 están disponibles?
- La memoria de activación y atención puede reducirse mientras el rendimiento aumenta en kernels capaces de FP8, particularmente en fases limitadas por la memoria.
- En entrenamientos de contexto largo (2k–8k tokens), FP8 más implementaciones modernas de atención reducen significativamente la huella y mejoran tokens/s, ayudando a mantener más del modelo fuera del camino de checkpointing.
- Perf/W mejora en estado estable cuando los kernels FP8 funcionan eficientemente, una tendencia establecida en Hopper y que se espera que continúe a medida que los kernels de Blackwell maduren.
El habilitamiento es el factor limitante. Las versiones de PyTorch 2.6+ emparejadas con CUDA 12.8 y cuDNN 9 proporcionan una base clara para la preparación para Blackwell. El paso decisivo es el soporte de marcos y kernels: atención, matmul y layernorm deben exponer rutas FP8 TE y retener la convergencia. Hasta que esas rutas estén ampliamente disponibles, BF16 sigue siendo el estándar, con FP8 habilitado selectivamente en subgráficos bien probados. Los primeros en adoptar deberían validar cuidadosamente la convergencia al activar FP8 en transformers, mantener constantes los hiperparámetros y registrar el tiempo hasta la pérdida objetivo junto con tokens/s.
Incluso antes de que se complete el habilitamiento de FP8, el ancho de banda bruto de Blackwell cambia el cálculo. Por ejemplo, el GeForce RTX 5090 combina 32 GB de GDDR7 con 1.792 TB/s, un nivel que acelera las fases limitadas por la memoria y aumenta el rendimiento en modelos de visión dominados por transformers. El SKU profesional de Blackwell extiende la memoria a 48 o 72 GB y ofrece hasta aproximadamente 1.344 TB/s en el modelo de 48 GB, añadiendo tanto capacidad como margen de ancho de banda para el entrenamiento.
FP4/FP6: lo que desbloquean primero y un camino seguro hacia su adopción
FP4 y FP6 llegan con los Tensor Cores de quinta generación de Blackwell. La promesa es clara: reducir a la mitad la huella de memoria nuevamente en comparación con FP8 para inferencia y ajustar más flujos de trabajo limitados por capacidad en una sola GPU. Pero los stacks de entrenamiento aún no están ahí para FP4 de propósito general. Las cadenas de herramientas públicas y los kernels ampliamente utilizados aún dependen de BF16/FP16 y FP8 para la aceleración de transformers donde están apoyados.